Using Sequence Numbers in SQL Server
Microsoft introduced the concept of Sequence Numbers in SQL Server 2012 which are:
... a user-defined schema-bound object that generates a sequence of numeric values according to the specification with which the sequence was created ...
This is similar to an Identity column in principle, but in practice it's quite different. Whilst an identity column is bound to a single table, a sequence number is an independent object that is essentially a "number generator" whose product can be used wherever, and however, you want. Creating one is very simple, here's a simple example (the full syntax for CREATE SEQUENCE can be found here):
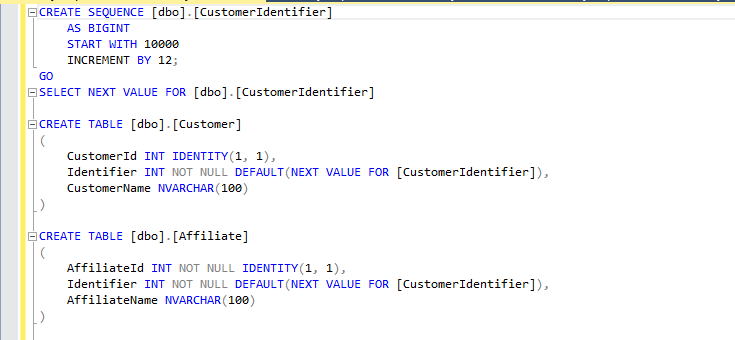
CREATE SEQUENCE [dbo].[CustomerIdentifier] AS INT START WITH 10000 INCREMENT BY 12; GO
This creates a new sequence number called CustomerIdentifier that's sized to the SQL Server INT data-type, will use 10,000 as the starting value and return subsequent numbers in the sequence by adding 12 each time. This could be achieved just as readily with an identity column, but that would be limited to being used for rows in a given table whereas there's no requirement that the generated values are persisted anywhere, or even used. Selecting a value from the sequence looks like this:
SELECT NEXT VALUE FOR [dbo].[CustomerIdentifier]
The full documentation for NEXT VALUE FOR shows where it can, and cannot be used, but running the simple query above after having created the CustomerIdentifier sequence would result in the number 10000 being returned, then 10012, then 10024 and so on.
One way sequence numbers can be used is to generate unique numerical identifiers for records across disparate tables. If, for example, you have an Affiliate table and a Customer table but didn't want to duplicate identifiers between them you could make use of the sequence in a default constraint on a column in each table:
CREATE TABLE [dbo].[Customer] ( CustomerId INT IDENTITY(1, 1), Identifier INT NOT NULL DEFAULT(NEXT VALUE FOR [CustomerIdentifier]), CustomerName NVARCHAR(100) ) CREATE TABLE [dbo].[Affiliate] ( AffiliateId INT NOT NULL IDENTITY(1, 1), Identifier INT NOT NULL DEFAULT(NEXT VALUE FOR [CustomerIdentifier]), AffiliateName NVARCHAR(100) )
Ignoring for one moment the fact that the tables are structurally identical (this is an example!) both of these have an Identifier column which is mapped to the CustomerIdentifier sequence to provide a unique id across both tables that can be used to refer to both customers and affiliates without duplication. Inserting a couple of rows into each table:
INSERT
INTO [dbo].[Customer]
(
CustomerName
)
VALUES ('John Smith'),
('Jane Smith')
INSERT
INTO [dbo].[Affiliate]
(
AffiliateName
)
VALUES ('Contoso Bank'),
('Wingtip Toys')
Gives the values in the Identifier column in sequence across the two tables:
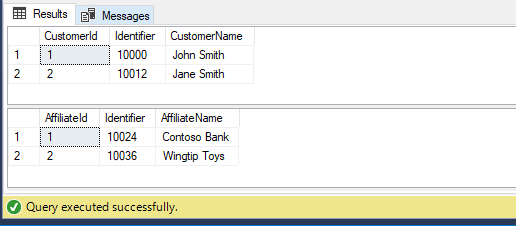
There are many other ways you can use sequences in SQL Server, described in detail in the previously linked documentation for the NEXT VALUE FOR function, with the above just being one example. I can think of several examples from the past (all of which pre-date my access to production infrastructure that was running SQL Server 2012) where it would've come in handy for a variety of reasons. What about you?